Appendix A. Methods used to estimate vital rates and compute bootstrap confidence intervals for sensitivities and elasticities.
For each population × year combination, we estimated the vital rates listed in Table A1, using the following methods.
In a preliminary analysis, we performed
logistic regressions of survival vs. size for each population separately, including
year as a categorical variable. To include all plants in these regressions,
we approximated the two-dimensional area of plants with 20 or fewer rosettes
by multiplying the number of rosettes times the area per rosette (estimated
from field data). These regressions showed significant (P ![]() 0.01) relationships between survival and size in three populations and a marginally
significant (P < 0.1) relationship in a fourth population, with larger
plants having a greater probability of surviving. However, the regression
equations consistently overestimated the survival of one-rosette plants, even
when squared and cubic terms were included in the model, indicating that rather
than changing smoothly with size, survival increases abruptly as plant size
goes from one to more than one rosette. When we excluded one-rosette plants
from the logistic regressions, size was a significant predictor of survival
in only one population. Although mortality was concentrated at the smaller
end of the size range, the total number of deaths of plants with two or more
rosettes was too small in most populations to see a significant effect of size
on survival. Hence we estimated separately the survival probability of
one-rosette plants (s3) and the survival probability of plants
with more than one rosette, and we used the later as the survival rate for classes
4 through 12 (i.e., s4 through s12; Table
A1).
0.01) relationships between survival and size in three populations and a marginally
significant (P < 0.1) relationship in a fourth population, with larger
plants having a greater probability of surviving. However, the regression
equations consistently overestimated the survival of one-rosette plants, even
when squared and cubic terms were included in the model, indicating that rather
than changing smoothly with size, survival increases abruptly as plant size
goes from one to more than one rosette. When we excluded one-rosette plants
from the logistic regressions, size was a significant predictor of survival
in only one population. Although mortality was concentrated at the smaller
end of the size range, the total number of deaths of plants with two or more
rosettes was too small in most populations to see a significant effect of size
on survival. Hence we estimated separately the survival probability of
one-rosette plants (s3) and the survival probability of plants
with more than one rosette, and we used the later as the survival rate for classes
4 through 12 (i.e., s4 through s12; Table
A1).
To estimate the rates at which surviving individuals undergo transitions to other size classes, we estimated the following vital rates for classes 3 through 12. The growth probability gj is the number of survivors initially in class j that grew into any larger class divided by the total number of survivors initially in class j. The reversion probability rj is the number of survivors shrinking to any smaller class divided by the number of survivors not growing; i.e., rj is the reversion probability conditional uponnot growing, so that (1–gj) rj is the probability that class j survivors shrink and (1–gj)(1– rj) is the probability that class j survivors remain in class j. For class j survivors, hij is the probability that individuals that grow advance by i classes, whereas kij is the probability that individuals that revert do so by i classes. By definition, r3 and g12 are zero (as one-rosette plants cannot revert to the seedling stage, and individuals in the largest class cannot grow).
One-rosette plants (class 3) were never observed to fruit, and plants with 2–5 rosettes (class 4) fruited only rarely (across the 5 populations, 4 plants produced a single fruit in 1057 plant-years of observation on individuals in this size range). Plants with 6–10 rosettes (class 5) had a higher, but still low, chance of setting fruits (14 plants made 1 or 2 fruits in 574 plant-years observed). In an average year, more than 10% of class 6 plants (11–20 rosettes) fruited, and there was a trend towards increasing numbers of fruits with an increase in the number of rosettes. To estimate fruit production for this class, we first performed a linear regression of fruit number on rosette number. The average of the predicted fruit numbers for each possible number of rosettes, weighted by the fraction of all class 6 plants in the population at the start of the census that had the corresponding number of rosettes, was used as the class 6 fruit production rate.
For plants with more than 20 rosettes (classes 7 through 12), fruit number usually increased more-or-less linearly or leveled off as cushion area increased, but for some population × year combinations, it increased and then declined. Lower average fruit production by large plants than by intermediate-sized plants is explained by reproductive senescence or by infection by the anther smut Microbotryum violaceum, which was present at modest frequencies in some of the study populations. To allow for the possibility that fruit production is a hump-shaped function of plant size, we modified the procedure we used for class 6 to estimate fruit production for larger classes. Specifically, we identified the maximum-likelihood estimates of the parameters in each of the following equations describing fruit number (F) vs. cushion area (A) (assuming Poisson-distributed errors):
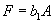 , ,
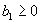
|
(A.1a)
|
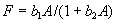 , ,
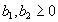
|
(A.1b)
|
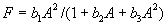 , ,
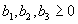
|
(A.1c)
|
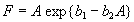 , ,
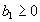
|
(A.1d)
|
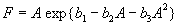 , ,
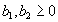
|
(A.1e)
|
Equation A.1a predicts a linear increase in fruit number with cushion area, Eqs. A.1b,c predict that fruit number approaches an asymptote as area increases, and Eqs. A.1d,e predict that fruit number is a hump-shaped function of area. The extra parameters give Eqs. A.1c and A.1e greater flexibility to fit the data than Eqs. A.1b and A.1d, but at the risk of over-fitting (Burnham and Anderson 1998). We identified the equation with the lowest value of the Akaike Information Criterion (Burnham and Anderson 1998) as being the most parsimonious (i.e., the one that provides the best fit to the data with the fewest parameters), and we used it as the best predictor of fruit number as a function of area. As a measure of the average fruit number fj across all individuals in class j, accounting for their different sizes, we used the expression
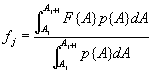
|
(A.2)
|
where F{A} is the best-fit version of Eqs. A.1, Aj is the cushion area at the lower boundary of class j, and p{A} is a probability density function describing the distribution of cushion areas among the plants in the data set. We found that a gamma distribution provided a close fit to the observed distributions of cushion area in the first year of the census, so we used fitted gamma distributions for p{A}. We used the largest observed size as the upper boundary for class 12. The integrals in Eq. A.2 were evaluated numerically using MATLAB.
As noted previously, we supplemented the population censuses with seed addition experiments at two populations. At the end of the 1996 growing season, we established 10 pairs of 50 × 50 cm quadrats immediately adjacent to the census transects at both the Pass and Ridge populations (the effort required to census these plots prevented us from establishing similar plots at the other 3 populations). In one plot from each pair ("addition plots"), we haphazardly scattered 400 moss campion seeds that we had harvested immediately before from the study populations (seeds were pooled across populations, but because fruit production was highest at the RG population, most seeds came from there). No seeds were added to paired "control plots". The following spring, we performed periodic censuses of all plots, counting the number of emerging seedlings and marking each with a wooden toothpick. By subtracting the total number of seedlings in control plots from the total number in addition plots, we estimated the number of seedlings in addition plots that had emerged from the seeds we had added (we set this number to zero when control plots had more seedlings than addition plots). We also censused the plots at the end of the summer to determine how many of the marked seedlings were still alive. We established new sets of control and addition plots in 1997, 1998, and 1999, using identical methods as in 1996 except that we added 200 seeds to 25 × 50 cm plots and (in 1998 and 1999) five addition plots received seeds produced by hermaphrodites and five by females. In contrast to shorter-term studies conducted in the greenhouse (Shykoff 1988) and the field (Delph and Mutikainen 2003), we found no differences in the number of surviving seedlings one or two years after sowing seeds produced by females vs. hermaphrodites, so we have lumped the two types of seeds in our analyses. Although no new seeds were added after the initial establishment of a set of addition plots, we continued to census older plots to look for delayed emergence as evidence of a seed bank, and to estimate the probability that a seedling survives to become a one-rosette plant.
We used the numbers of seedlings emerging over subsequent years to estimate two vital rates: s0, the one-year survival rate of seeds in the seed bank, and g, the probability that a surviving seed will germinate in the spring. Specifically, we used maximum likelihood (assuming binomially distributed errors) to fit the function
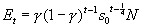
|
(A.3)
|
to
the total number of seedlings emerging in the spring of the tth year
after addition, Et , given the initial number of seeds, N. The
right hand side of Eq. A.3 reflects the facts that to emerge in the following
spring, a live seed in the seed bank at the time of our late August census must
first survive approximately ¾ of a year (i.e., until early June, when
most germination occurs), and that to emerge in year t, a seed cannot
have germinated in any previous year (probability 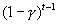 ). As
data were pooled across years to estimate
). As
data were pooled across years to estimate ![]() and s0, we have no estimates of year-to-year variation in
these vital rates.
and s0, we have no estimates of year-to-year variation in
these vital rates.
We also used data from the seed
addition plots to estimate two additional vital rates. We calculated s1,
the probability that a newly emerged seedling survives its first summer of life,
as the proportion of seedlings marked in spring still alive at the fall census. To
estimate s2, the probability that a seedling survives to the
end of the following summer to be censused as a one-rosette plant, we performed
a multiple regression of the number of one-rosette plants in one year against
both the number of seedlings and the number of one-rosette plants in the preceding
year, using both the control and addition plots as sampling units. The
regression coefficient for seedlings estimates the seedling survival rate, s2. To
obtain a sufficient sample size for this regression, we pooled data from all
plots and all years within a population; therefore we do not have separate annual
estimates of s2. Data from the seed plots allowed us
to obtain separate estimates of the vital rates s0, s1,
s2, and ![]() for the PA and RI populations. For the other 3 populations, we used the
average of the two estimates of each vital rate.
for the PA and RI populations. For the other 3 populations, we used the
average of the two estimates of each vital rate.
The two remaining vital rates ![]() and
and ![]() are components of reproduction. As
noted in the text, the number of seeds per fruit
are components of reproduction. As
noted in the text, the number of seeds per fruit ![]() was estimated by averaging the number of seeds in mature fruits collected at
the Ridge site in 1997. This single estimate was used for all populations
and years. We found that scattering seeds across the seed addition plots
resulted in much higher numbers of seedlings emerging than is characteristic
of naturally dispersed seeds in most populations, the majority of which simply
fall within the cushion by which they were produced and fail to germinate. Hence
we needed to estimate
was estimated by averaging the number of seeds in mature fruits collected at
the Ridge site in 1997. This single estimate was used for all populations
and years. We found that scattering seeds across the seed addition plots
resulted in much higher numbers of seedlings emerging than is characteristic
of naturally dispersed seeds in most populations, the majority of which simply
fall within the cushion by which they were produced and fail to germinate. Hence
we needed to estimate ![]() , the
probability that a seed lands in a safe site in which it has a non-zero chance
of germinating. As the total density of plants in our transects changed
very little over the 6 years of our study, we assumed that the long-term stochastic
growth rate
, the
probability that a seed lands in a safe site in which it has a non-zero chance
of germinating. As the total density of plants in our transects changed
very little over the 6 years of our study, we assumed that the long-term stochastic
growth rate ![]() s
(see Eq. 2 in the text) is close to 1 in all 5 populations. For each population
and year, we substituted the estimates of all other vital rates into the annual
projection matrices, multiplied the reproduction terms (i.e., the appropriate
elements in the first two rows of each matrix) by
s
(see Eq. 2 in the text) is close to 1 in all 5 populations. For each population
and year, we substituted the estimates of all other vital rates into the annual
projection matrices, multiplied the reproduction terms (i.e., the appropriate
elements in the first two rows of each matrix) by ![]() ,
and varied its value until the long-term population growth rate
,
and varied its value until the long-term population growth rate ![]() s
was 1. This procedure yielded a single estimate of
s
was 1. This procedure yielded a single estimate of ![]() for each population. For the Pass population, we set
for each population. For the Pass population, we set ![]() at its maximum value of 1, which predicted a slowly declining population. Because
we were forced to estimate
at its maximum value of 1, which predicted a slowly declining population. Because
we were forced to estimate ![]() without field data, we did not calculate or analyze the sensitivities or elasticities
of this vital rate.
without field data, we did not calculate or analyze the sensitivities or elasticities
of this vital rate.
In summary, for each population
we were able to obtain separate yearly estimates for most vital rates, although
for 5 rates (s0, s2, ![]() ,
,
![]() , and
, and ![]() )
only a single average estimate was obtained. The vital rate estimates are
given in the Supplement.
)
only a single average estimate was obtained. The vital rate estimates are
given in the Supplement.
We computed percentile bootstrap confidence intervals for sensitivities and elasticities as follows. For each population and year, we drew a random sample with replacement from the data on marked plants present in the population that year. In each sample, the number of plants in each size class equaled the number in the corresponding class in the original data set, but a typical sample included some of the original plants more than once and others not at all. We rejected an alternative procedure of randomly choosing once among individual plants and using their entire 5 year histories to estimate the series of vital rates, because it would have lead to years in which no individuals were present in some size classes (and hence the vital rates for those classes in those years could not have been estimated). In a separate procedure, we drew with replacement a random sample of 10 pairs of control and seed addition quadrats from the PA site and 10 pairs of quadrats from the RI site. As we sampled at the level of quadrat pairs, our bootstrapping procedure differs from that of Kalisz and McPeek (1992) and McPeek and Kalisz (1993), who sampled at the level of individual seeds within plots. Kalisz and McPeek used experimental seed banks in which known numbers of seeds were sown into sterile soil. Because any seedling or viable seed encountered later in these seed banks must have been one of the seeds initially added, Kalisz and McPeek could determine exactly what fraction of the added seeds in each seed bank experienced each possible fate, and used those fractions as expected proportions when drawing bootstrap samples for each seed bank. In contrast, both our seed addition and control plots contained an unknown number of naturally dispersed seeds. Our method relies on the difference between the total number of emerging seedlings across all seed addition vs. control quadrats to correct for input of naturally dispersed seeds, and bootstrapping at the level of quadrat pairs reflects this key aspect of our design. By choosing quadrat pairs (rather than randomly choosing 10 seed addition and 10 control quadrats), we retain any similarity in natural seed input that may have occurred in adjacent quadrats in the field. We drew the mean number of seeds per fruit from a normal distribution with mean and standard deviation equal to the mean and standard error, respectively, of the number of seeds per fruit in the sample of fruits collected at the RI site in 1997 (see text).
For each bootstrap sample, we then followed exactly the procedures described above to estimate the vital rates for each of the 5 years. If the growth rate gi for any class i was zero for all 5 years, that sample was discarded, as a model in which larger size classes cannot be reached from smaller size classes is not biologically realistic (survival and fecundity estimates were never zero for all 5 years). Finally, we used the vital rate estimates to construct annual matrices and to compute the stochastic sensitivities and elasticities for the vital rate means and variances, as described in the text. For each population, we generated a total of 1000 five-year sets of vital rate estimates. From the resulting distributions of 1000 estimates for each sensitivity or elasticity, we computed a percentile 95% confidence interval as described in Dixon 2001.
Burnham, K. P., and D. R. Anderson. 1998. Model selection and inference: a practical information-theoretic approach. Springer, New York, New York, USA.
Delph, L. F., and P. Mutikainen. 2003. Testing why the sex of the maternal parent affects seedling survival in a gynodioecious species. Evolution 57:231–239.
Dixon, P. 2001. The bootstrap and the jackknife: describing the precision of ecological indices. Pages 267–288 in S. M. Scheiner and J. Gurevitch, editors. Design and Analysis of Ecological Experiments. Second Edition. Oxford University Press, Oxford, UK.
Kalisz, S., and M. A. McPeek. 1992. Demography of an age-structured annual: resampled projection matrices, elasticity analyses, and seed bank effects. Ecology 73:1082–1093.
McPeek, M. A., and S. Kalisz. 1993. Population sampling and bootstrapping in complex designs: demographic analysis. Pages 232–252 in S. M. Scheiner and J. Gurevitch, editors. Design and analysis of ecological experiments. Chapman and Hall, New York, New York, USA.
Shykoff, J. A. 1988. Maintenance of gynodioecy in Silene acaulis (Caryophyllaceae): stage-specific fecundity and viability selection. American Journal of Botany 75:844–850.
TABLE A1: Definition of vital rates used in constructing projection matrices.
Symbol:
Definition:
Temporal variability:
Vital rates describing survival
s0
Probability a seed survives a year in the seed bank
Constant†
s1
Probability a newly germinated seedling survives its first
growing season (3 months)
Variable
s2
Probability a seedling survives a year to become a one-
rosette plant
Constant1
s3
Probability a one-rosette plant survives a year
Variable
sj,
4
j
Probability a plant originally in class j survives a year
(a single value for classes 4 through 12 in a given year)
Variable
Vital rates describing growth and reversion
gj,
3
Probability a surviving individual originally in class j grows
to a larger class the following year
Variable
rj,
4
Probability a surviving individual starting in class j but not
growing reverts to a smaller size class the following year
Variable
hi,j,
4
Probability an individual from class j that grows does so by i
size classes
Variable‡
ki,j,
4
Probability an individual from class j that reverts does so by
i size classes
Variable2
Vital rates describing aspects of reproduction
Mean number of seeds per fruit
Constant1
Probability a seed disperses to a safe site
Constant2
Probability a seed alive in the seed bank in spring germinates
Constant1
fj,
4
Number of fruits produced in a year by an average individual
in size class j
Variable
†Sensitivities and elasticities to variances not calculated.
‡No sensitivities or elasticities calculated (see Methods: Estimation of Vital Rates).